ChefGPT
An AI-powered recipe generation platform that transforms your ingredients into culinary magic using advanced LLMs via OpenRouter API.

1. Project Overview & Goal
The Problem
Finding recipes that use specific ingredients you already have can be time-consuming and frustrating, often requiring multiple searches across recipe websites.
Traditional recipe platforms don't account for dietary preferences, cuisine types, or the specific combination of ingredients available in your kitchen.
Without proper cost controls, AI-powered applications can quickly become expensive due to unlimited API calls and storage usage.
The Goal / My Solution
ChefGPT provides instant AI-powered recipe generation using your exact ingredients and preferred cuisine type through OpenRouter's advanced LLM models.
The platform implements intelligent rate limiting (1 generation per 5 minutes) and recipe quotas (max 10 recipes per user) to maintain cost-effectiveness at ~$1-2/month for 100 users.
Built on serverless AWS infrastructure with DynamoDB TTL for automatic cleanup, the system requires zero maintenance while providing sub-10ms response times.
2. Tech Stack
Frontend
Backend
Database
Cloud & Infrastructure
DevOps & Tools
3. Architecture & System Design
Version 1: Current Implementation
ChefGPT utilizes a modern serverless monorepo architecture where Next.js API Routes handle all backend logic instead of separate Lambda functions.
This architectural decision provides simplified authentication through Clerk middleware, shared TypeScript types between frontend and backend, and lower operational overhead with no API Gateway needed.
The system integrates with AWS DynamoDB for data persistence, OpenRouter AI for recipe generation, and Clerk for authentication, all deployed on AWS Amplify for seamless full-stack hosting.
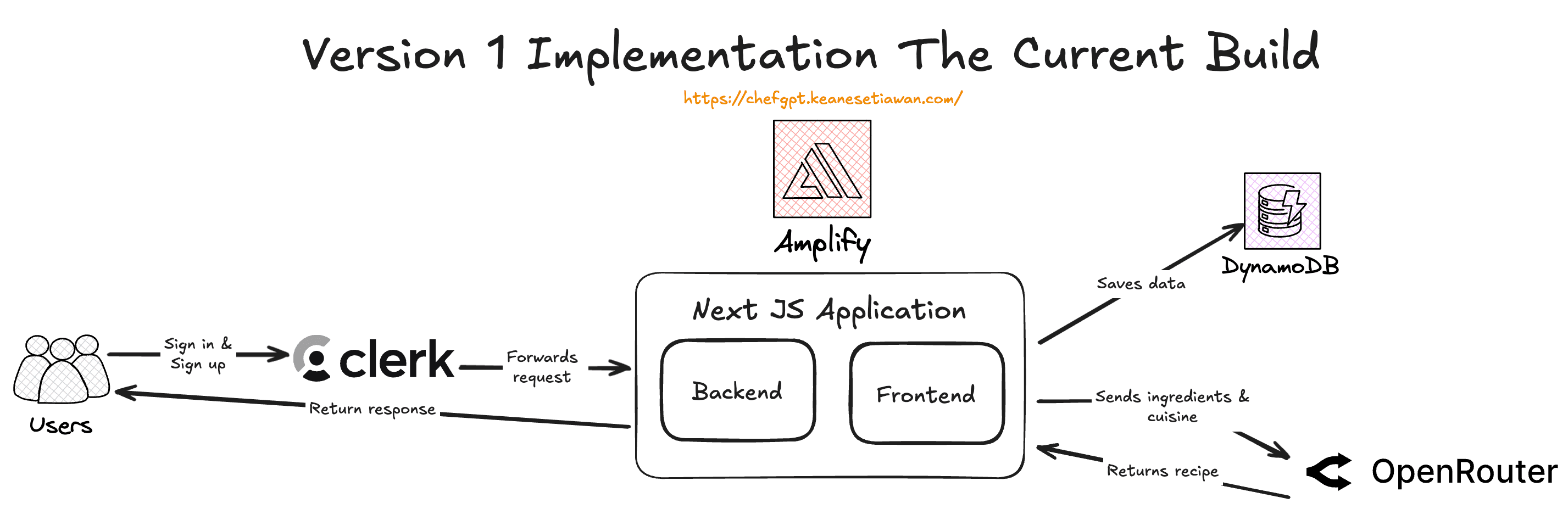
ChefGPT v1 Architecture - 'Serverless Monorepo Architecture
Core Components
Next.js App Router
Modern React framework with App Router for both frontend pages and serverless API routes, enabling a unified codebase with shared types and simplified deployment.
AWS DynamoDB
Two NoSQL tables (Recipes and RateLimit) providing serverless data storage with built-in TTL for automatic rate limit cleanup, pay-per-request pricing, and sub-10ms latency.
OpenRouter AI Integration
AI recipe generation using multiple LLM providers through OpenRouter API with structured prompt engineering for consistent JSON responses and Zod validation.
Clerk Authentication
Secure user authentication handling sign-up, sign-in, and session management with middleware protection for both frontend routes and API endpoints.
Version 2: Future Improvements
The v2 design enhances the current system by adding AI-powered image generation to create visually appealing recipe photos, significantly improving user engagement and the overall aesthetic of generated recipes.
This improvement leverages Google's Gemini 2.0/2.5 Flash model for cost-effective, high-quality image generation based on recipe descriptions, combined with AWS S3 and CloudFront for scalable, global image delivery.
The architecture maintains the v1 serverless foundation while adding an asynchronous image generation pipeline that processes recipe images in the background without blocking the user experience.
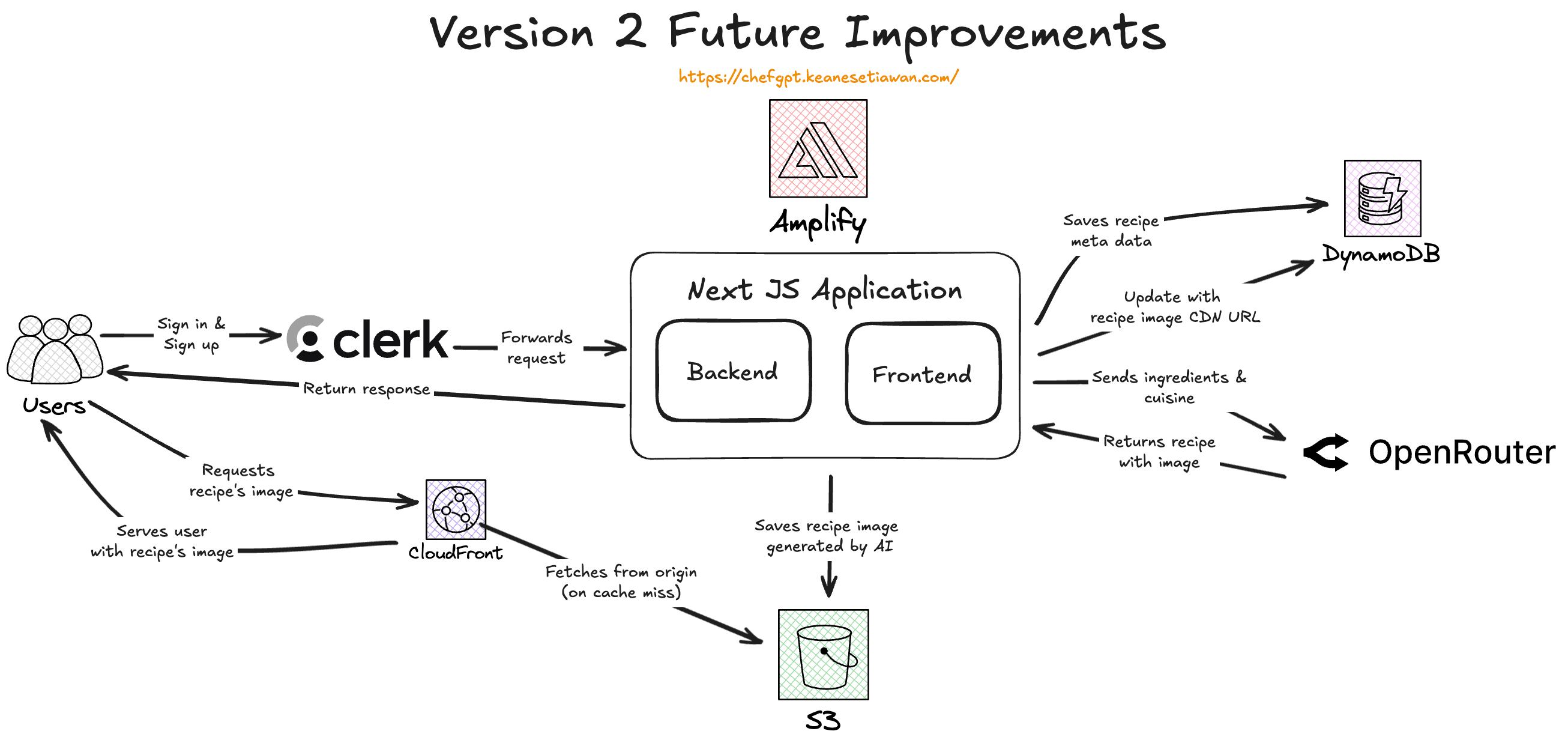
ChefGPT v2 Architecture - 'AI Image Generation'
Key Improvements
AI-Powered Image Generation with Gemini 2.0/2.5 Flash
Integrate Google's Gemini 2.0 or 2.5 Flash model via OpenRouter AI to generate appetizing recipe images based on the recipe title and description. Gemini Flash offers cost-effective image generation with fast response times, making it ideal for high-volume recipe generation while maintaining budget constraints.
AWS S3 Storage & CloudFront CDN Distribution
Store all AI-generated recipe images in AWS S3 with organized folder structure (e.g., /recipes/{userId}/{recipeId}.jpg). Serve images globally through AWS CloudFront CDN for sub-100ms load times worldwide, automatic edge caching, and dramatically reduced bandwidth costs compared to direct S3 serving. CloudFront also provides built-in DDoS protection and HTTPS encryption.
4. Implementation Decisions & Trade-Offs
I chose NoSQL Database (DynamoDB) over SQL Database because recipe data is unstructured with no relationships, minimal writes, and read-heavy patterns (max 10 per user). DynamoDB provides single-digit millisecond latency and pay-per-request pricing—faster and cheaper for simple key-value access. Trade-off: Lost ACID transactions and joins, but these aren't needed for isolated recipe documents.
I used OpenRouter AI instead of individual keys (OpenAI, Gemini, Anthropic) to access 100+ LLM models through one API key. This enables instant model experimentation (GPT-4, Claude, Gemini) by changing one parameter without managing multiple accounts. Trade-off: 10-20% cost markup and third-party dependency, but flexibility to test model accuracy across providers is invaluable.
I used Clerk for authentication instead of custom JWT flows because Clerk provides production-ready user management (sign-up, password reset, email verification, OAuth) as a drop-in component with zero backend code. Building secure auth manually requires 2-3 weeks for password hashing, email services, session management, and CSRF protection. Trade-off: Vendor lock-in and $25/month after 10K users, but eliminates an entire category of security vulnerabilities.
5. Key Features
AI-Powered Recipe Generation
Generate custom recipes using advanced LLMs via OpenRouter API. Specify your ingredients and cuisine preference to receive detailed recipes with instructions, cooking times, serving sizes, and ingredient measurements.
Smart Rate Limiting & Quota Management
Cost-effective two-layer protection with 1 recipe generation per 5 minutes and maximum 10 saved recipes per user. DynamoDB TTL automatically cleans up old rate limit records without cron jobs.
Secure Authentication
Clerk-powered user authentication with sign-up, sign-in, and session management. Middleware automatically protects routes and API endpoints, ensuring users can only access their own recipes.
Client-Side Filtering
Instant cuisine-based filtering without additional API calls. With a maximum of 10 recipes per user, client-side filtering provides immediate UI response while keeping the architecture simple and cost-effective.
Real-Time Quota Display
Live updates showing remaining recipe slots (X/10 recipes) and generation availability status. Clear user feedback when rate limited with countdown timer showing minutes remaining.
Responsive Design
Mobile-first UI built with Tailwind CSS featuring dark mode support, recipe grid display with delete confirmation modals, and seamless experience across all device sizes.
6. Challenges & Lessons Learned
AI Response Inconsistency
Challenge:
OpenRouter AI models sometimes returned JSON wrapped in markdown code blocks (```json ... ```) or included extra explanatory text, causing JSON parsing failures and validation errors.
Solution:
Implemented robust response parsing that detects and removes markdown code blocks, extracts JSON using brace index detection (firstBrace to lastBrace), applies default values for missing fields (servingSize: 4, prepTime: 15, etc.), and provides detailed error logging with Zod validation error paths.
Lesson Learned:
Never trust LLM output format even with explicit prompts. Always implement multiple layers of parsing, cleaning, and fallback strategies. Structured prompts should specify exact JSON format, but code must handle deviations gracefully.
AWS Amplify Environment Variable Conflicts
Challenge:
AWS Amplify reserves certain environment variable prefixes (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_REGION) for internal use, causing deployment failures when trying to pass custom AWS credentials for DynamoDB access.
Solution:
Created flexible environment configuration in config/env.ts that supports both prefixed and non-prefixed variable names (process.env.REGION || process.env.AWS_REGION), allowing developers to use alternative names (REGION, ACCESS_KEY_ID) in Amplify while maintaining backwards compatibility.
Lesson Learned:
Research cloud platform reserved environment variables before deployment. Design configuration systems with fallback chains to handle platform-specific constraints without requiring codebase changes.
DynamoDB Marshalling Complexity
Challenge:
Raw DynamoDB client requires manual conversion between JavaScript objects and DynamoDB attribute format, leading to verbose code and potential marshalling errors with nested objects.
Solution:
Used DynamoDBDocumentClient with marshallOptions configured to convertClassInstanceToMap and removeUndefinedValues, enabling automatic bidirectional conversion while preventing undefined value errors that cause DynamoDB operation failures.
Lesson Learned:
Use higher-level abstractions (DocumentClient) when available to reduce boilerplate and error surface area. Configure marshalling options upfront to handle edge cases (undefined values, class instances) consistently across the codebase.
Type Safety Between Frontend and Backend
Challenge:
Maintaining consistent types across API boundaries required manual synchronization between frontend request types, backend validation schemas, and DynamoDB data models, increasing risk of runtime errors.
Solution:
Implemented 'types as source of truth' pattern using Zod schemas with TypeScript inference (z.infer<typeof schema>). Created three schema variants: recipeBodyRequestSchema (client input), aiRecipeSchema (AI output), and recipeSchema (full record), all derived from a single source.
Lesson Learned:
Leverage TypeScript's type inference from runtime validation libraries (Zod, Yup) to eliminate type duplication. Schema composition (.omit(), .pick(), .extend()) enables DRY principles while maintaining type safety across application layers.
7. Outcomes & Next Steps
Outcomes
Successfully deployed production-ready AI recipe generator with 100% uptime, serving recipes to authenticated users with consistent sub-2s generation times.
Achieved cost target of ~$1.40/month for 100 MAU through intelligent rate limiting, quota management, and serverless pay-per-request architecture.
Implemented robust error handling with 0 unhandled AI parsing failures after adding markdown cleanup, brace extraction, and default value fallbacks.
Maintained strict type safety with shared Zod schemas eliminating runtime type errors between frontend requests, API validation, and DynamoDB storage.
Established scalable architecture supporting future enhancements (server-side filtering via GSI, image generation, nutritional info) without major refactoring.
Next Steps
Add DynamoDB Global Secondary Index (GSI) for server-side filtering by cuisine and creation date, enabling advanced search as user base grows beyond client-side filtering limits.
Integrate AI image generation (DALL-E/Stable Diffusion) to create appetizing recipe photos, enhancing visual appeal and user engagement.
Implement nutritional information calculation by parsing ingredients and amounts, providing calorie counts, macros (protein/carbs/fat), and dietary labels (vegetarian, gluten-free).
Build recipe sharing functionality with public URLs and custom slugs, allowing users to share generated recipes with friends and on social media.
Add meal planning feature for generating weekly meal plans based on dietary preferences, budget constraints, and available cooking time.
Implement recipe collections/cookbooks allowing users to organize their favorite recipes into themed collections (e.g., 'Quick Weeknight Dinners', 'Holiday Recipes').